I have architected and delivered end-to-end data platforms and microservice ecosystems that enabled self-service analytics, operational resilience, and measurable business outcomes. These platforms span data lakes, governed semantic layers, real-time event streams, and microservices-based reporting systems for large industrial and SaaS customers.
Enterprise Data Platform Modernization
Consolidated siloed on-prem and cloud data into a governed data lake using Apache Iceberg on object storage (Parquet format). The platform provided:
- ACID-compliant table formats with time-travel and schema evolution (Iceberg).
- Parquet storage for performant columnar analytics and reduced storage cost.
- Object storage integration (MinIO / S3 compatible) for cheap, scalable storage.
- Data cataloging, dataset lineage, and role-based access for governed self-service.
Impact: reduced analytical ETL time by 60–80%, enabled trusted metrics across teams, and accelerated dashboard delivery for business stakeholders.
Microservices Reporting Platform
Designed a microservices-first reporting architecture to replace a monolithic reporting stack. Key elements:
- Event-driven ingestion with Kafka (high-throughput buffering & replayability).
- Stream processing (Spark/Flink) for near-real-time aggregation and feature extraction.
- Isolated reporting microservices exposing semantic APIs consumed by BI tools.
- Multi-tenant design with quota and governance boundaries for each tenant/region.
Outcome: report latency cut from hours to minutes, elastic scale to handle peak ingestion, and a clear separation between platform and BI layers for faster feature rollout.
NLP-Based Conversational Analytics Platform
Built an NLP/MCP reporting interface that converts complex BI queries into plain language — enabling non-technical users to interrogate license and usage data without analyst dependency.
- LLM integration (Claude, Gemini, GPT) for natural language query parsing.
- Semantic layer mapping user intent to governed dataset APIs.
- Context-aware responses with drill-down into underlying data.
Impact: simplified BI adoption for enterprise customers — reduced onboarding friction and improved product stickiness.
AI-Based Monitoring & Anomaly Detection Platform
Implemented predictive alerting and AI-driven anomaly detection across microservices — replacing reactive incident response with proactive intelligence.
- ML-based baseline modelling for service health metrics.
- Automated anomaly classification and severity scoring.
- Integrated runbook triggers for common incident patterns.
Outcomes: 50% reduction in downtime, 20% reduction in support tickets.
SaaS Activation, License Monitoring & Optimization
Built SaaS lifecycle services for activation/deactivation, usage telemetry, and license optimization (used within OpenLM product initiatives).
- Centralized license registry with usage events streamed to analytics.
- Automation for license provisioning and policy-driven deactivation.
- Cost dashboards and recommendations to reclaim unused licences.
Resulted in measurable license cost reduction for customers and improved governance over SaaS spend.
Operational Observability & CI/CD
Delivered platform reliability through robust CI/CD pipelines, infra-as-code, and observability stacks:
- Automated builds, tests, and canary deployments for microservices (GitHub Actions / Jenkins).
- Logging/metrics tracing (Prometheus + Grafana + OpenTelemetry) for end-to-end visibility.
- Alerting and runbook integration to reduce MTTR and support SRE workflows.
Effect: stable rollouts with predictable lead times and a visible reduction in incident durations.
Governance, Security & Data Contracts
Implemented governance controls and data contracts to enable safe self-service:
- Row/column-level access controls and attribute-based access for datasets.
- Data contracts and schema checks preventing downstream breakages.
- Secure credentials management and auditing for object stores and service principals.
This provided the confidence for analytics teams to ship new dashboards without manual gatekeeping.
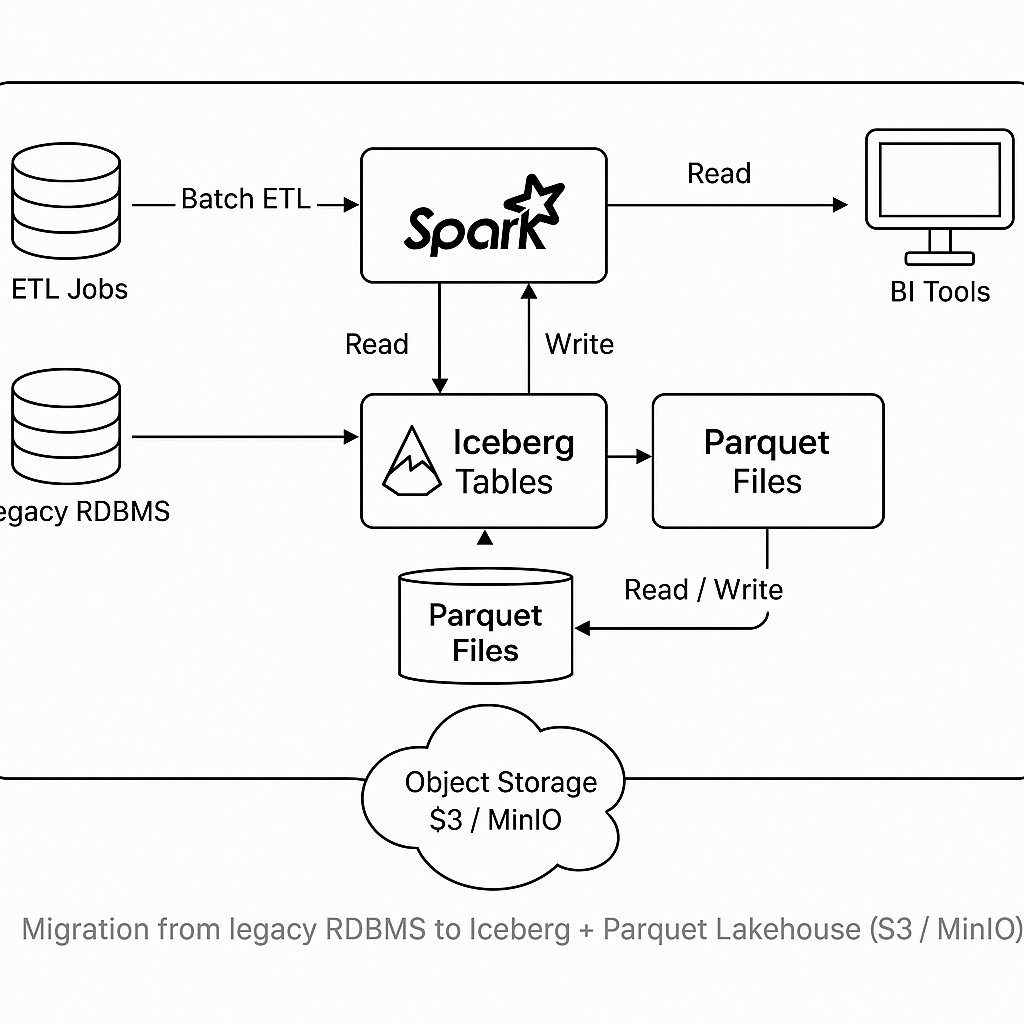
Case Study: Migrating to Apache Iceberg + Parquet
At one of the largest privately owned steel companies in Indonesia, I led the migration of analytics data from traditional relational data stores into a modern data lakehouse architecture based on Apache Iceberg with Parquet as the columnar format. The project required balancing cost, governance, and analytical performance across multiple regions.
Objectives
- Unify siloed departmental data into a central, queryable store.
- Enable schema evolution without downtime or re-ingestion.
- Reduce report generation time for management dashboards.
- Lay a foundation for real-time analytics pipelines.
Approach
- Deployed MinIO for object storage with S3 compatibility.
- Adopted Apache Iceberg table format for ACID guarantees and time-travel queries.
- Re-partitioned raw data into Parquet files for efficient scanning.
- Introduced Spark SQL as the query engine, connected to BI tools (Power BI / QuickSight).
- Implemented metadata refresh jobs and catalog sync for governance.
Results
- Batch ETL windows reduced from 8 hours to ~2 hours.
- Ad-hoc query performance improved by 60–70%.
- Enabled reproducible analysis with time-travel queries.
- Storage costs reduced by leveraging compressed Parquet.
Migration Checklist
- 🔍 Assess current data volume, schema complexity, and retention needs.
- 📂 Identify landing zone (object storage, MinIO/S3, HDFS).
- ⚙️ Define partition strategy (by time, region, product, etc.).
- 🧩 Convert legacy tables to Parquet, validate against queries.
- 📑 Register tables in Iceberg catalog (Glue/Hive/REST catalog).
- 🛠️ Update ETL jobs to write to Iceberg instead of RDBMS.
- 📊 Connect BI tools (Power BI, QuickSight, Superset) to new tables.
- 🔄 Monitor performance, optimize file sizes, compaction, and caching.
This case study demonstrated how open formats and modern table management systems can transform traditional industrial analytics into a future-ready lakehouse platform.
Figure: Migration from legacy RDBMS to Iceberg + Parquet Lakehouse (S3/MinIO).
Representative Tech Stack
Kafka, Spark/Flink, Apache Iceberg, Parquet, MinIO / S3, PostgreSQL / ClickHouse, Docker & Kubernetes, Prometheus/Grafana, OpenTelemetry, GitHub Actions / Jenkins, Python, Java, and Node.js.
Business Outcomes — Sample Metrics
- Report latency: from ~3–6 hours → 2–5 minutes for core business reports.
- ETL window shrink: 60–80% reduction in batch processing time (Parquet + Iceberg optimizations).
- License spend: single-digit % to mid-teens % reduction in wasted SaaS licensing via automated reclamation.
- MTTR (incidents): decreased by ~40% after observability and runbook automation.
How I work with clients / teams
I partner with product owners, architects, and operations to translate business outcomes into a phased technical roadmap. Early emphasis is placed on:
- Clearly defined SLAs and success metrics.
- Small, deliverable-aligned milestones to show early ROI.
- Automation and governance that scale without bottlenecks.